December 13, 2019 / by Trustworthy AI team
Risk, simulation, and the road to trustworthy autonomous vehicles
We perform the first independent evaluation of a commercially available AV policy, Comma AI’s OpenPilot. Using the TrustworthySearch API, we efficiently identify and rank failure modes of the system. We estimate OpenPilot will encounter dangerous situations approximately once every 1250 miles.
Autonomous vehicle testing today
The risks of autonomous vehicle (AV) technologies remain largely unknown. A handful of fatal accidents involving AVs highlight the importance of testing whether the system, as a whole, can safely interact with humans. Unfortunately, the most straightforward way to test AVs—in a real-world environment—requires prohibitive amounts of time due to the rare nature of serious accidents. Specifically, a recent study demonstrates that AVs need to drive “hundreds of millions of miles and, under some scenarios, hundreds of billions of miles to create enough data to clearly demonstrate their safety” [Kalra, 2016]. To reduce the time, cost, and dangers of testing in the real world, the field has largely turned to simulation-based testing methods.
![This graph produced by RAND Corporation details the number of miles necessary to statistically validate AV performance relative to human drivers. Due to frequent updates it is impossible to validate such claims via naive Monte Carlo estimates even with industrial-scale cloud computing. [Kalra, 2016]](/assets/images/rand.png)
Most popular strategies for simulation-based testing are built upon decades of techniques developed for validating traditional software systems. Nevertheless, the complexities of modern AV pipelines push the boundaries of these approaches and draw out significant limitations.
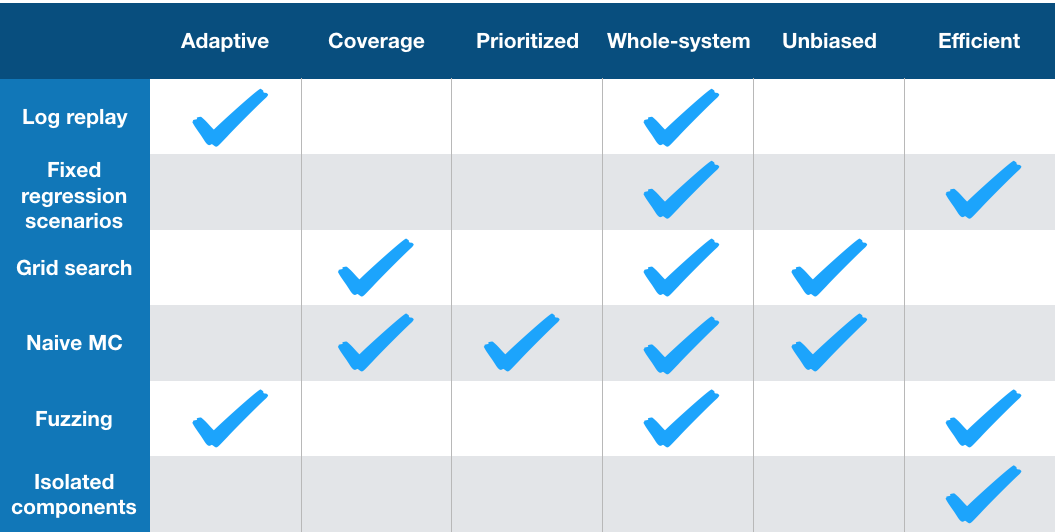
Specifically:
-
Log replay and fixed regression scenarios do not provide coverage as they cannot create new failure modes. They are also biased.
-
Grid search can never scale to cover the natural parameterizations of even simple scenarios.
-
Naive Monte Carlo estimates are tried and true but suffer from excessive simulation requirements (see RAND report) in scenarios where failure is rare or the search space is high-dimensional.
-
Fuzzing is a classic technique in software engineering and has previously been publicly espoused by Waymo. It does not provide coverage or unbiased estimates, but it can capture adversarial search directions.
-
Isolated component verification has become popular in academia, but it never tests at boundaries of system interfaces and does not scale to realistic neural networks or system dynamics.
In the next section we outline how our solution combines the positive characteristics of naive Monte Carlo and fuzzing to provide six desired features that we believe are necessary for succesful simulation-based testing of AVs.
How autonomous vehicle testing needs to change
Motivated by the shortcomings of existing approaches, we identify necessary components of a testing framework should have the following features:
Safety: Real world public road testing puts others lives in danger. Initial tests must be done in a controlled setting (e.g. simulation or closed courses).
Efficiency: Industrial AV systems have regular updates. Safety testing must efficiently find failures and regressions at the pace of development (e.g. daily).
Coverage: Understanding coverage of test scenarios is essential to evaluating the true performance of an AV policy. Finding a one-off adversarial situation amounts to finding a minimum in the landscape of AV performance. In contrast, coverage means finding all high-likelihood failure scenarios, or the area of the performance landscape which is below an acceptable level. This latter quantity is required for accurate estimates of risk.
Adaptivity: Adaptive testing prevents overfitting to previously-defined scenarios or failure modes.
Unbiasedness: Unbiasedness implies that estimates of risk are not systemically warped by priors or previous performance.
Prioritized results: For accurate and actionable insights, safety testing must rank and prioritize failures. In particular, the relative importance of modes within the long tail of failures should be quantified.
While the above features are necessary for effective AV policy evaluations, they are not sufficient for creating a scalable tool for continuous integration. Both internal and third-party testing should utilize methods which test the AV policy as a whole system in a black-box fashion.
Black-box interaction: Testing a whole system as a black box maintains its integrity and confidentiality. Integrity ensures we capture as accurately as possible the true risk of an AV policy. Combining tests of individual components does not yield this result, and inserting a scaffolding for testing interfaces between components can fundamentally change the nature of failures. Confidentiality of internal system behavior ensures there is no leakage of proprietary knowledge about the AV policy’s design; this is especially important to establish cooperation of AV manufacturers with regulators or third-party testers.
A risk-based framework for AV testing
To solve for the desired features of a testing system, we propose a risk-based framework. The risk-based framework utilizes a base distribution of scenarios (possible world configurations) with associated probabilities. Then we efficiently search through this high-dimensional space to find failures. We don’t only search to see if the system fails; we use events which are near-misses to guide the search to progressively more dangerous situations. For a detailed technical explanation, see our paper that we presented at the NeurIPS Machine Learning for Autonomous Driving Workshop this year [Trustworthy AI, 2019].
Testing Comma AI’s OpenPilot with the TrustworthySearch API
With these three components—the risk-based framework, an efficient failure-search algorithm, and a blackbox simulation system—we perform the first independent evaluation of a commercially available AV policy, Comma AI’s OpenPilot.
OpenPilot is a SAE Level 2 [Comma AI, 2019A] driver-assistance system designed to be integrated with the Comma AI’s proprietary camera hardware and a customized software platform. OpenPilot has been installed on more than 4500 vehicles and driven more than 10 million miles [Comma AI, 2019B]. A lack of publicly discussed incidents suggests that it is a capable system, but no rigorous statistics have been released regarding its safety or performance.

We use the TrustworthySearch API to find and rank failures of the Comma AI system in simulation. Below is an example of one of the crashes we identified.
This failure is at the interface of the perception system and the planning system. OpenPilot utilizes a model predictive control (MPC) scheme to adjust the vehicle’s speed and steering angle. In this example, neither the MPC nor the perception system fail. The perception system, blinded by the sun, correctly interprets that it is uncertain about the position of the lead vehicle. The MPC is given the estimated pose of the lead vehicle and plans a safe trajectory relative to its knowledge of the world. Unfortunately, the constraints in the MPC don’t treat the uncertainty of the estimated pose in a conservative manner, allowing the ego-vehicle to accelerate into the back of the lead vehicle. This type of integrated system failure cannot be found by investigating either system in isolation.
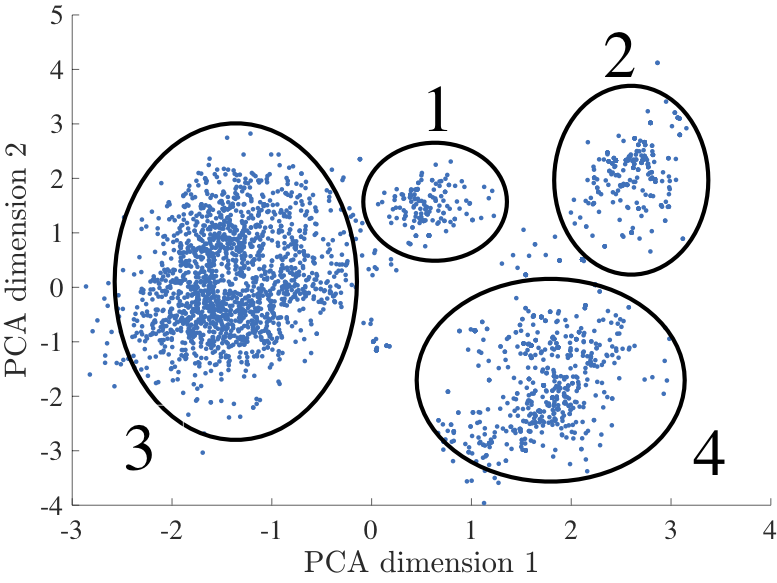
Rather than looking at one failure in isolation, TrustworthySearch provides coverage by identifying the set of failure modes. In order to look at these failure modes we perform a PCA analysis which reveals four clusters of crashes. Whereas the first PCA mode largely characterizes changes in weather conditions (e.g. sunlight in clusters 1 and 3 vs. rain in clusters 2 and 4), the second PCA mode characterizes changes in relative velocities between vehicles (low relative velocity in clusters 1 and 2 vs. high relative velocity in clusters 3 and 4). Weather and lighting conditions are key factors in each of the failure clusters. This is in line with expectations due to the algorithm’s heavy reliance on visual input.

Conclusions
The TrustworthySearch API offers significant speedups over real-world testing, allows efficient, automated, and unbiased analysis of AV behavior, and ultimately provides a powerful tool to make safety analysis a tractable component in AV design. We believe that rigorous safety evaluation of AVs necessitates adaptive benchmarks that maintain system integrity and prioritize system failures. The framework presented in this paper accomplishes these goals by utilizing adaptive importance-sampling methods which require only black-box access to the policy and testing environment. As demonstrated on Comma AI’s OpenPilot, our approach provides a principled, statistically-grounded method to continuously improve AV software. More broadly, we believe this methodology can enable the feedback loop between AV manufacturers, regulators, and insurers that is required to make AVs a reality. Please contact us at contact@trustworthy.ai if you are interested in learning more about our product or accessing a demo of our API.
Link to full paper: https://arxiv.org/abs/1912.03618
References
- N. Kalra and S. M. Paddock. Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability? Transportation Research Part A: Policy and Practice, 94:182–193, 2016.
- Trustworthy AI. Efficient Black-box Assessment of Autonomous Vehicle Safety. https://arxiv.org/abs/1912.03618
- Comma AI. Openpilot. https://github.com/commaai/openpilot, 2019.
- Comma AI, May 2019. URL https://twitter.com/comma_ai/status/1123987351276068864.